前言
在上一篇文章中,我们讲解了在Ubuntu环境下安装Anaconda,并且做出了英文的简易词云。
可能会有的同学尝试把文章换成中文的,做出中文词云。我想大家得到的结果肯定是这样的
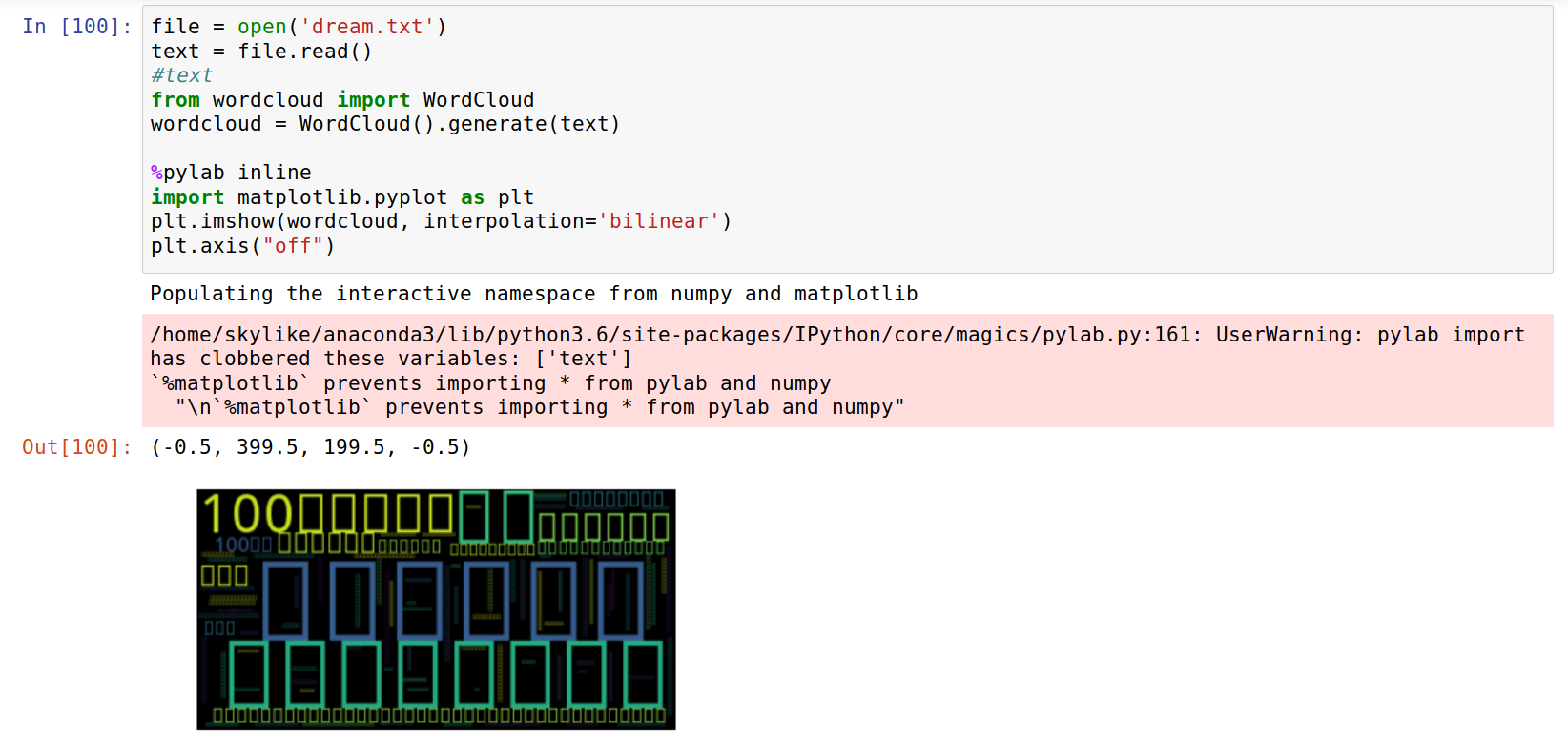
中文与英文在编码上是存在很多区别的,而且我们做英文词云的时候,在一篇文章中,单词之间是通过空格分开的,
但是中文并没有使用空格。所有就有了上面的图片。那么中文如何分词呢?我们需要用到一款工具,jieba(结巴)
准备工作
1.文本数据,作为分析的对象。这是必须的,这次我选用的是上一次相关的文本数据
我有一个梦想的中文版本。做成Dream.txt文件,保存在和代码相同的目录下。
2.Anaconda工具套装,上一篇文章已经讲过如何安装和使用,这里不在啰嗦。
3.worldcloud ,作词云用的Python扩展工具包。
4.jieba 中文分词用的扩展包。
5.simsum.tty 中文字体包,用于显示中文。
第一步
打开终端输入以下命令,安装jieba扩展包
pip install jieba //安装很简单,没什么可说的继续在终端输入
jupyter notebook //打开代码编辑器,并切换到存放Dream.txt的目录下如果你做了上次那个因为词云,那就用上次那个目录就可以了,在代码编辑器输入以下代码
file = open('Dream.txt')
text = file.read()
text
出现这样的字样,说明文本数据没有问题,可以正常打开。
分词
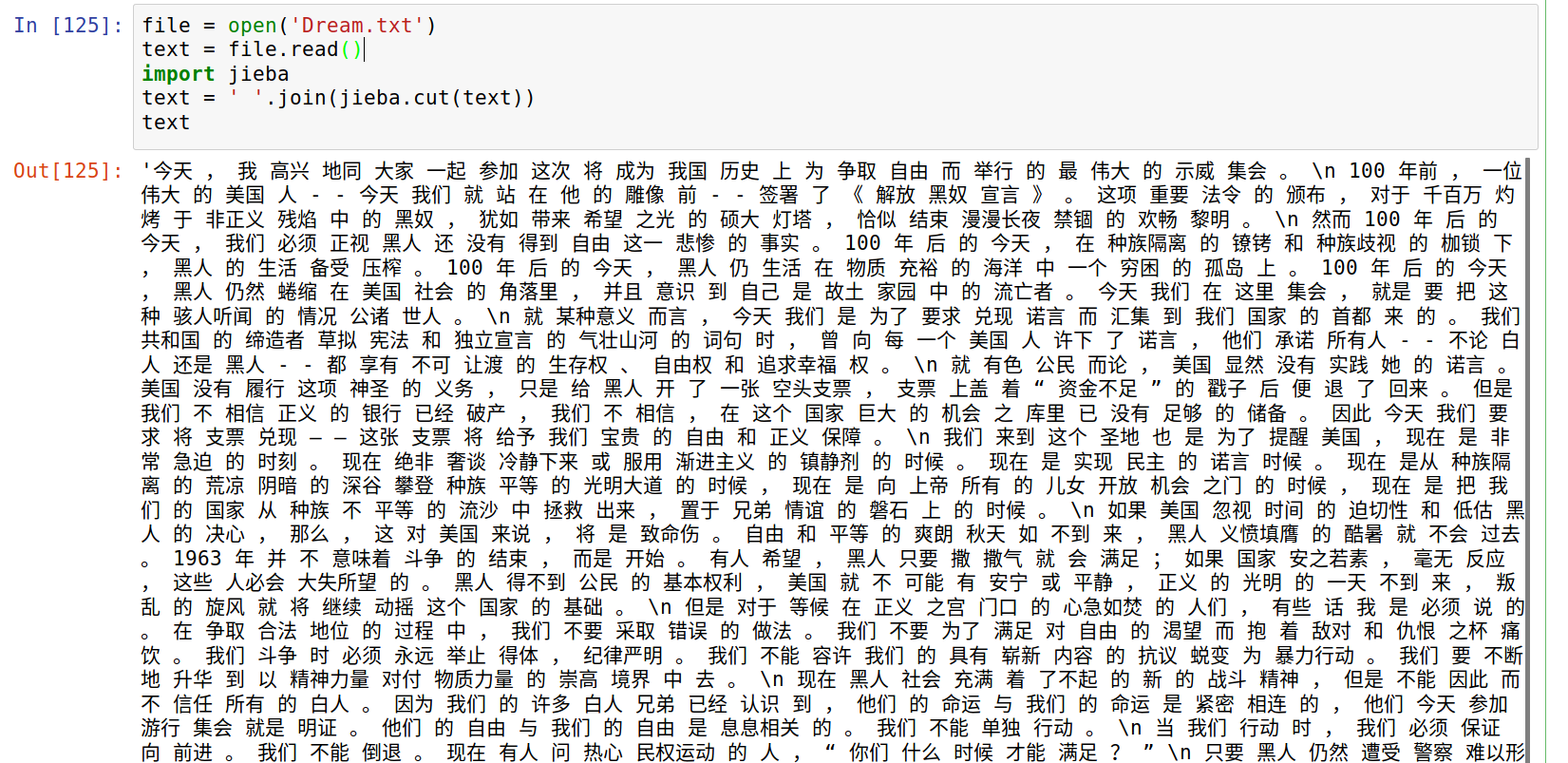
在第二和第三行之间,插入以下代码,进行分词操作
import jieba //导入jieba分词包
text = ' '.join(jieba.cut(text)) //对中文进行分词你将会看到以下的画面,说明分词成功了
词云生成
注释掉代码最后的text,以防干扰。继续在编辑器里输入
from wordcloud import WordCloud
wordcloud = WordCloud().generate(text)此时如果没有报错,也没有任何输出,那是不是词云就已经分析完成了呢?
并不是,但这次和上次的英文不一样,因为我们要输出中文的词云,所以我们
准备了simsum.tty的字体包,把它放在代码相同的目录下,然后在代码编辑器输入以下代码:
from wordcloud import WordCloud
wordcloud = WordCloud(font_path="simsun.ttf").generate(mytext)依然没有输出,但这次离成功不远了。
词云输出
在代码编辑器里面输入以下代码:
%pylab inline
import matplotlib.pyplot as plt
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")你将看到以下结果,请无视警告

一张简易的中文词云就做好啦!!!

