
网络爬虫(又被称为网页蜘蛛,网络机器人,是一种按照一定
的规则,自动地抓取万维网信息的程序或者脚本。
前言
在讲爬虫之前,我们需要知道我们是如何从网络上获取信息的,有人说,百度啊,谷歌啊!!!!!
没错,大多时候,我们都是利用他们从网络上面获取我们的信息的,其实搜索引擎也是爬虫的一种,他们的爬每天都有成千上万的爬虫在互联网上不断的爬去各种各样的信息,存到他们的数据库,做出索引,通过复杂的算法做成搜索引擎。你可以把互联网想象成一个蜘蛛网,每个节点就是一个网站,一个域名,上面有一个蜘蛛爬来爬去,收集各个网站的信息,这个蜘蛛就是爬虫。
随着网络的迅速发展,互联网拥有无穷无尽的信息,如何有效地提取并利用这些信息成为一个巨大的挑战。
在这个人人都说big-data,信息满天飞的时代,不会点儿爬虫技术都不好意思和别人打招呼,掌握网络爬虫与信息提取技术,你可以快速的从互联网上获取你需要的信息,不用去伪造,发问卷去收集数据。那么如何写网络爬虫呢?
HTTP协议
我们是如何访问互联网的?
打开电脑上了浏览器,在上面的地址栏输入https://www.jd.com
按一下回车,京东的首页就会出现在我们的面前。
这个过程就是一次访问互联网的过程,京东就是我们的访问目标 我们就是通过
这么一个url(https://www.jd.com)去访问互联网的,这个过程是通过HTTP协议
实现的。那么HTTP协议是什么?

超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。1960年美国人Ted Nelson构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了HTTP超文本传输协议标准架构的发展根基。Ted Nelson组织协调万维网协会(World Wide Web Consortium)和互联网工程工作小组(Internet Engineering Task Force )共同合作研究,最终发布了一系列的RFC,其中著名的RFC 2616定义了HTTP 1.1。
HTTP是一个基于“请求与响应”模式的、无状态的应用层协议
HTTP协议采用URL作为定位网络资源的标识,URL格式如下:
protocol://hostname[:port]/path/[parameters][?query] //带[]的为可选项第一部分(protocol)
模式/协议(scheme):它告诉浏览器如何处理将要打开的文件。最常用的模式是超文本传输协议(Hypertext Transfer Protocol,缩写为HTTP),这个协议可以用来访问网络。
还有其他的协议:
http 超文本传输协议资源
https 用安全套接字层传送的超文本传输协议
ftp 文件传输协议
mailto 电子邮件地址
ldap 轻型目录访问协议搜索
file 当地电脑或网上分享的文件
news Usenet新闻组
gopher Gopher协议
telnet Telnet协议
ed2k 电驴下载协议第二部分
文件所在的服务器的名称或IP地址,后面是到达这个文件的路径和文件本身的名称
host: 合法的Internet主机域名或IP地址
port: 端口号,默认为80和443端口
path: 请求资源的路径URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。url举例:
http://www.baidu.com
http://192.168.1.1HTTP协议对资源的操作方法
GET 请求获取URL位置的资源
HEAD 请求获取URL位置资源的响应消息报告,即获得该资源的头部信息
POST 请求向URL位置的资源后附加新的数据
PUT 请求向URL位置存储一个资源,覆盖原URL位置的资源
PATCH 请求局部更新URL位置的资源,即改变该处资源的部分内容
DELETE 请求删除URL位置存储的资源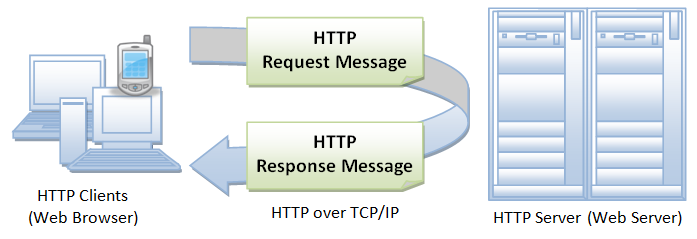
Python的Requests库
说了这么多,有啥用?
上面讲的这些都是我们平时手动访问互联网的方法,我们是要写网络爬虫,程序自动访问互联网。
所以,一个很现实的问题出现了,Python如何访问互联网?尴尬。。。
在Python中,有很多库可以访问互联网,比如urllib , Requests , scrapy等用于获取网页信息的模块
在学习的过程中,我们可以先选择一种,其他都差不多的。那么这次我们选用Requests。我认为他
更简单,更易用。
Anaconda工具套装中默认安装了这个库。可以参照以前的文章安装Anaconda套装.
或者打开终端,输入安装命令,安装非常简单,没有什么可说的;
pip install requests我们测试一下安装的结果,打开jupyter notebook,新建一个Python代码编辑器,输入以下代码:
import requests //引入requests库
r = requests.get(https://www.baidu.com) //以get的方式访问百度
print(r.status_code) //打印连接的状态码,200表示连接成功
200 //请求成功,返回内容
204 //请求成功,不返回内容
301 //请求的资源永久移动
304 //资源重定向
403 //请求被拒绝
404 //请求的资源不存在
503 //服务器故障requests库有7个方法,与HTTP协议一一对应
requests.request() 构造一个请求,支撑以下各方法的基础方法
requests.get() 获取HTML网页的主要方法,对应于HTTP的GET
requests.head() 获取HTML网页头信息的方法,对应于HTTP的HEAD
requests.post() 向HTML网页提交POST请求的方法,对应于HTTP的POST
requests.put() 向HTML网页提交PUT请求的方法,对应于HTTP的PUT
requests.patch() 向HTML网页提交局部修改请求,对应于HTTP的PATCH
requests.delete() 向HTML页面提交删除请求,对应于HTTP的DELETErequests.request() 方法是requests库的基本方法
requests.get(url, params=None, **kwargs)
∙ url : 拟获取页面的url链接
∙ params : url中的额外参数,字典或字节流格式,可选
∙ **kwargs: 12个控制访问的参数
Requests库两个重要对象是Response和Request
Response包含爬虫返回的内容,Responsed对象的属性
r.status_code HTTP请求的返回状态,200表示连接成功,404表示失败
r.text HTTP响应内容的字符串形式,即,url对应的页面内容
r.encoding 从HTTP header中猜测的响应内容编码方式
r.apparent_encoding 从内容中分析出的响应内容编码方式(备选编码方式)
r.content HTTP响应内容的二进制形式
Responsed的编码,内容中的实际编码才是我们需要的,打印text是是按照HTTP header中的编码,所以,
如果编码不一致,我们需要让他们一致。输入一行代码即可
r.encoding = r.apparent_encodingr.encoding 从HTTP header中猜测的响应内容编码方式
r.apparent_encoding 从内容中分析出的响应内容编码方式(备选编码方式)
r.encoding:如果header中不存在charset,则认为编码为ISO‐8859‐1
r.text根据r.encoding显示网页内容
r.apparent_encoding:根据网页内容分析出的编码方式
可以看作是r.encoding的备选讲完了requests库,我们可以实际试一下,没有实际操作都是瞎逼逼,我们用实例来看看吧!!!
实例
爬取京东小米6的商品信息,在代码编辑器输入以下代码:
import requests
r = requests.get('https://item.jd.com/4957824.html')
print(r.text)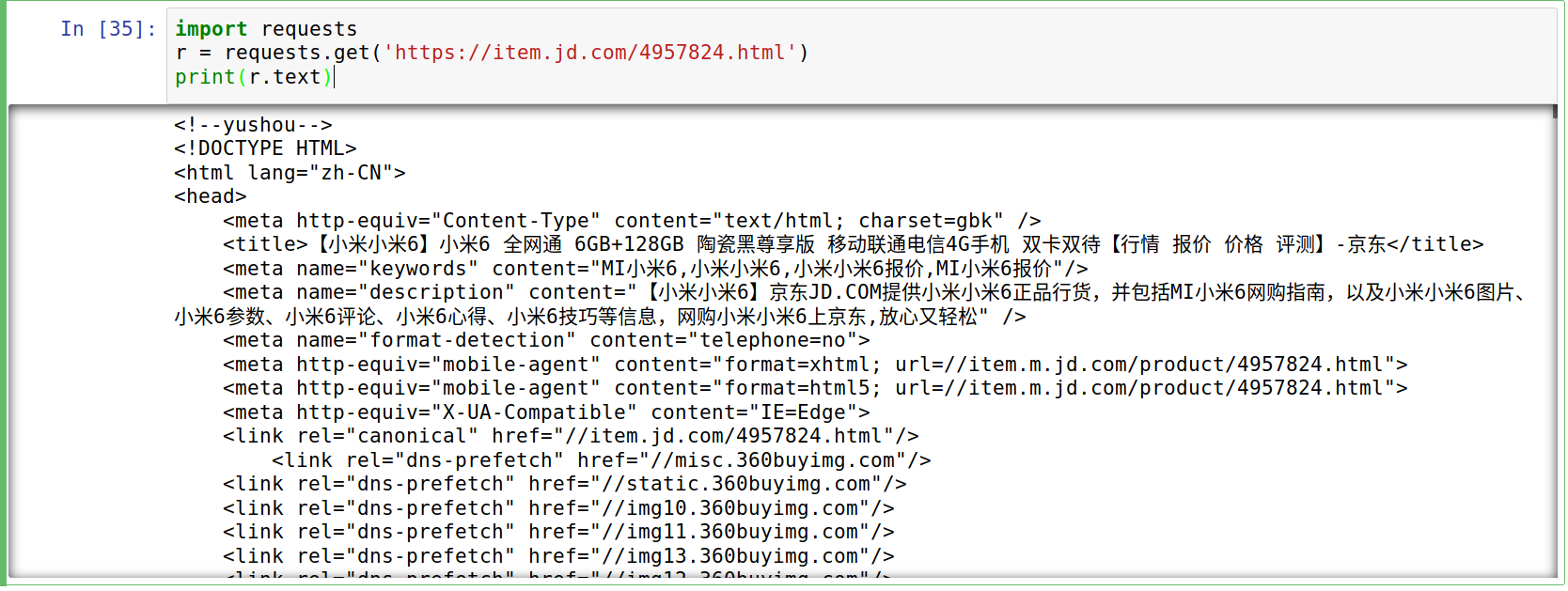
可以看到,返回了京东小米6的商品页面信息。是不是非常简单!!!
那我们也可以去亚马逊看看,把url改成:
https://www.amazon.cn/Alienware-%E5%A4%96%E6%98%9F%E4%BA%BA-15C-R2738S-15-6%E8%8B%B1%E5%AF%B8%E6%B8%B8%E6%88%8F%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%94%B5%E8%84%91/dp/B06WVM5SQX/ref=sr_1_1?ie=UTF8&qid=1505224864&sr=8-1&keywords=%E5%A4%96%E6%98%9F%E4%BA%BA
我们看到返回的东西,完全不知道是什么,而且长度也非常小,这么复杂的页面。
一开始我们可以怀疑是编码问题,看一下编码,果然不一致
r.encoding //HTTP响应头中的编码
r.apparent_encoding //根据文本内容猜测的编码打印r.text的时候是按照HTTP响应中的编码打印的,完全不一致啊!!!!
在编辑器里面输入以下代码,让他们一致就好

我们发现了不友好的内容,看一下HTTP的状态码,然而返回的是503 , 而不是我们喜欢的200
原因是,亚马逊通过HTTP请求头,发现来源并不是浏览器,而是爬虫,所以重定向了错误的页面
当然,我们也可以修改HTTP请求头,让亚马逊以为我是流量器,是正常的用户访问

这样看起来就比较舒服的了,那么平时我们经常会看到这种的错误,那么我们可以使用异常处理
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text)
except:
print("Error_get")总结
requests在小规模爬虫的应用非常广泛,可以继续挖掘他的应用!!!

