在讲HashMap之前,先说说Java中的集合框架
Java 的集合框架
Java 中集合主要分为java.util.Collection和java.util.Map两大接口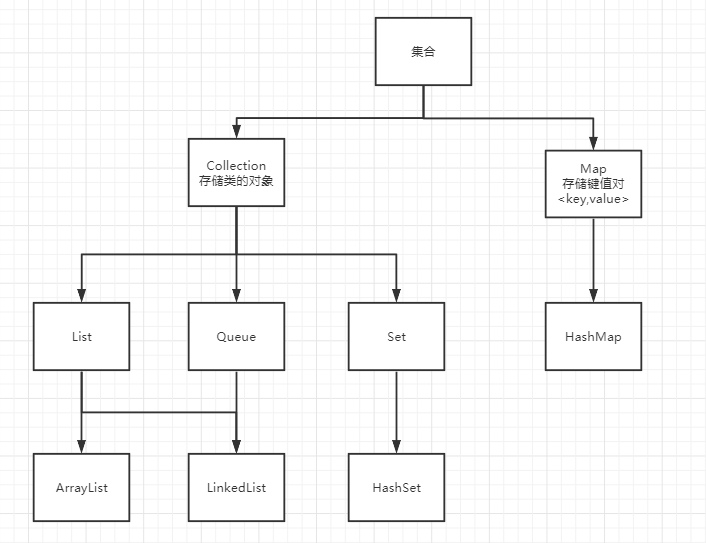
List,Set,Map三者区别
- List:线性表,必须按照顺序保存元素,有序,允许重复;
- Queue:队列,按照排队规则来确定对象产生的顺序,有序,允许重复;
- Set:集合,一组可变数量的数据项,无序,不能重复
- Map:使用键值对存储。Map会维护与Key有关联的值。两个Key可以引用相
同的对象,但Key不能重复, 典型的Key是String类型, 但也可以是任何对象。
java.util.Map接口的实现可用于表示“键”(key)和“值”(value)对象之间的映射。一个映射表示一组“键”对象,其中每一个“键”对象都映射到一个“值”对象。因此可以通过键来查找值。
HashMap
Map
Map是以键值对(key-value)的形式存储的对象之间的映射,key-value是以java.util.Map.Entry类型的对象实例存在。
Map可以使用键来查找值,一个映射中不能包含重复的键,但值是可以重复的。每个键最多只能映射到一个值。
HashMap 实现类
HashMap是java.util.Map接口最常用的一个实现类,前面所学的HashSet底层就是通过HashMap来实现的,HashMap允许使用null键和null值。null作为键只能有一个
HashMap的构造方法
HashMap():构造一个新的空映射;默认的初始容量为 16(最常用),负载系数为 0.75;
HashMap(int initialCapacity):构造一个新的空映射; 具有指定的初始容量,负载系数为 0.75;
HashMap(int initialCapacity, float loadFactor):构造一个新的空映射; 支持的 HashMap 实例具有指定的初始容量和指定的负载系数;
HashSet(Map<? extends K, ? extends V> m):构造一个新映射,其中包含指定映射相同。
HashMap常用的成员方法
- void clear():从该映射中删除所有映射;
- Set<Map, Entry<K, V>> entrySet:返回此映射中包含的映射的集合;
- V get(Object key):返回指定键映射到的值,如果该映射不包含键的映射,则返回 null;
- Set
keySet:返回此映射中包含的键的结合; - V put(K key, V value):将指定值与此映射中指定键关联;
- V remove(Object key):如果存在,则从此映射中删除指定键的映射。
- Collection
values:返回此映射中包含的集合。
HashMap数据结构
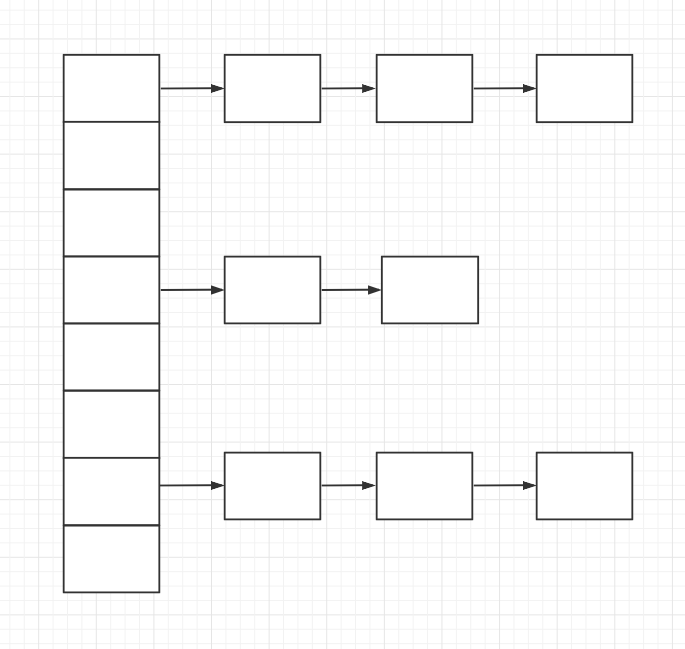
JDK1.8前
- HashMap 底层是数组和链表结合在一起使用也就是链表散列。
- HashMap 通过key 的hashCode经过扰动函数处理过后得到hash值,然后通过(n - 1) & hash判断当前元素存放的位置
- 所谓扰动函数指的就是HashMap 的hash 方法。使用hash 方法也就是扰动函数是为了防止一些实现
比较差的hashCode()方法 - 使用扰动函数之后可以减少碰撞
拉链法
将链表和数组相结合。也就是创建个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表后面
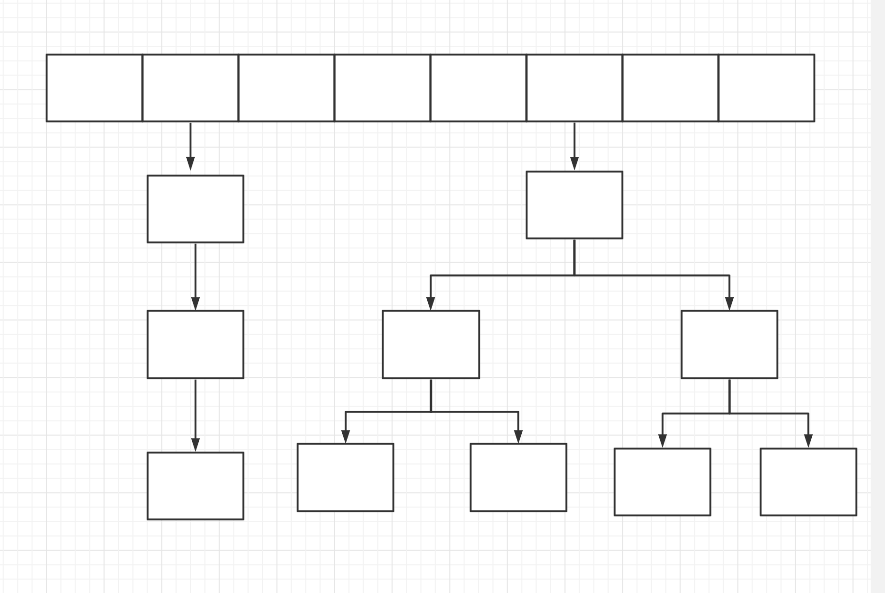
JDK1.8后
- JDK1 .8之后在解决哈希冲突时有了很大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
- 而链表长度小于6时,又会将红黑树转化成链表
HashMap装载因子
装载因子为什么是0.75
提高空间利用率和 减少查询成本的折中,主要是泊松分布,0.75的话碰撞最小,
HashMap有两个参数影响其性能:初始容量和装载因子。容量是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子是哈希表在其容量自动扩容之前可以达到多满的一种度量。
当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行扩容,扩容后的哈希表将具有两倍的原容量。
过高过低会怎么样
加载因子过高,例如为1,虽然减少了空间开销,提高了空间利用率,但同时也增加了查询时间成本;
加载因子过低,例如0.5,虽然可以减少查询时间成本,但是空间利用率很低,同时提高了rehash操作的次数。
选择0.75作为默认的加载因子,完全是时间和空间成本上寻求的一种折中选择
在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少rehash操作次数,所以,一般在使用HashMap时建议根据预估值设置初始容量,减少扩容操作。
HashMap的put方法
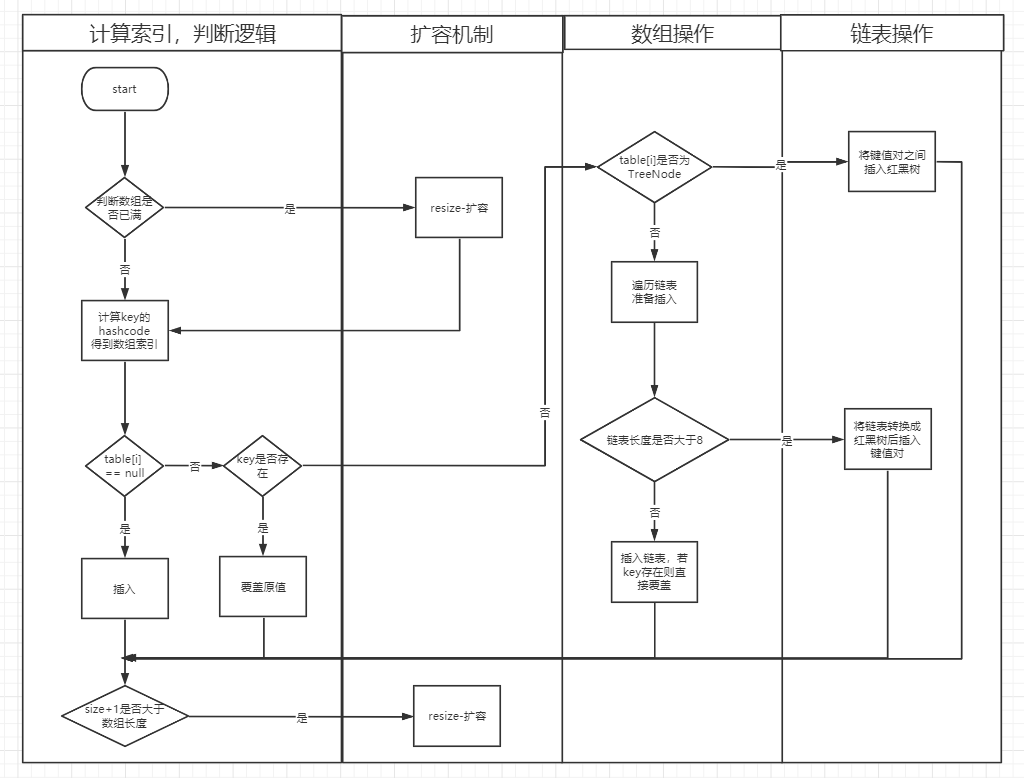
判断HashMap的数组table[i]是否为空或为null,否则执行resize()进行扩容;
根据键值key计算hashcode得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向步骤6,如果table[i]不为空,转向步骤3;
判断table[i]的元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;也就是完全相同
判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向步骤5;
遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value;
插入成功后,判断实际存在的键值对数量size是否超过了最大容量threshold,如果超过,进行扩容。

